

OpenAI déploie GPT-5.5, un nouveau modèle conçu pour gérer des tâches plus longues, plus complexes et plus autonomes dans ChatGPT comme dans Codex. Il est déjà disponible pour les utilisateurs Plus, Pro, Business et Enterprise, tandis que GPT-5.5 Pro arrive sur les offres Pro, Business et Enterprise. Pour les développeurs, les analystes et les équipes métier, l’enjeu est clair : confier davantage de travail à l’IA, avec moins d’instructions étape par étape.
GPT-5.5 vise les tâches longues avec moins d’intervention humaine
GPT-5.5 marque une nouvelle étape dans la stratégie d’OpenAI : transformer ChatGPT et Codex en outils capables de prendre en charge des missions plus longues, plus floues et plus techniques.
Le modèle est orienté vers la programmation agentique, l’analyse de données, la recherche, le traitement de documents et l’utilisation d’outils logiciels. Il ne s’agit donc plus seulement de générer une réponse ou un bout de code, mais de planifier une tâche, l’exécuter, modifier des fichiers, lancer des vérifications et ajuster le résultat.
OpenAI affirme aussi que GPT-5.5 conserve, en usage réel, la latence par token de GPT-5.4. Le modèle serait donc plus performant sans devenir sensiblement plus lent.
Les performances progressent sur la programmation agentique
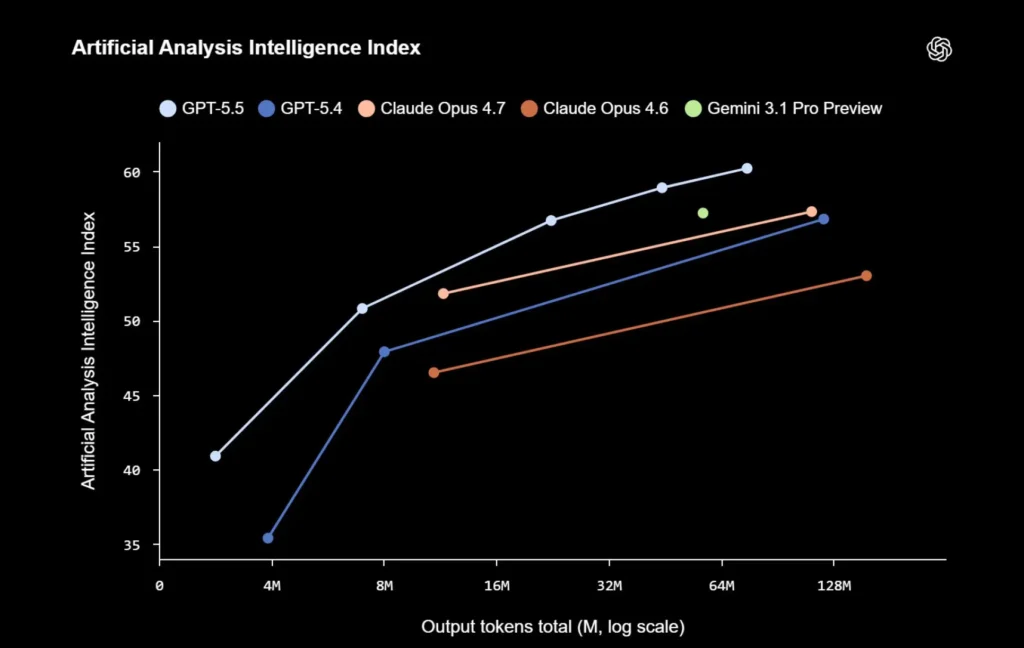
OpenAI présente GPT-5.5 comme son modèle le plus avancé à ce jour pour la programmation. Le progrès le plus visible concerne les scénarios où l’IA doit manipuler un projet, tester du code, corriger des erreurs et valider le résultat.
Sur Terminal-Bench 2.0, un benchmark centré sur des flux complexes en ligne de commande, GPT-5.5 atteint 82,7 %, contre 75,1 % pour GPT-5.4.
Le modèle obtient aussi 58,6 % sur SWE-Bench Pro, une évaluation fondée sur la résolution de problèmes réels issus de GitHub. Sur Expert-SWE, un test interne composé de tâches de développement longues, avec une durée médiane estimée à 20 heures pour un humain, GPT-5.5 monte à 73,1 %, contre 68,5 % pour GPT-5.4.
OpenAI met également en avant un gain d’efficacité : GPT-5.5 utiliserait moins de tokens que GPT-5.4 pour accomplir les mêmes tâches dans Codex. Pour les gros projets, où le contexte peut vite devenir massif, ce point peut avoir un impact direct sur les coûts et la fluidité du travail.
ChatGPT et Codex deviennent plus utiles pour les équipes métier
Dans ChatGPT, GPT-5.5 Thinking est destiné aux problèmes difficiles, à la synthèse d’informations, à l’analyse, à la recherche et aux tâches liées à des documents complexes.
Dans Codex, le modèle va au-delà de la génération de code. Il peut produire des documents, des tableaux au format Excel et des présentations. Il peut aussi agir sur des interfaces logicielles grâce à ses capacités d’utilisation de l’ordinateur.
OpenAI indique que plus de 85 % de ses employés utilisent Codex chaque semaine, dans des équipes aussi variées que le développement logiciel, la finance, la communication, le marketing, l’analyse de données et la gestion produit.
L’entreprise cite notamment un cas interne dans la finance : l’analyse de 24 771 formulaires fiscaux K-1, soit 71 637 pages. Ce traitement aurait permis à l’équipe concernée de gagner deux semaines de travail.
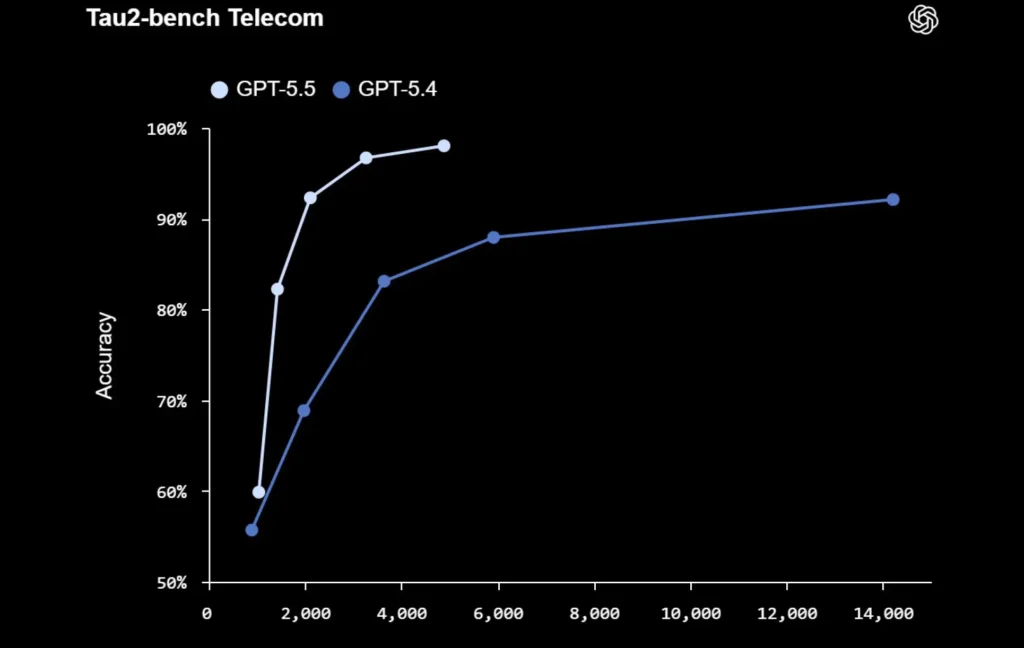
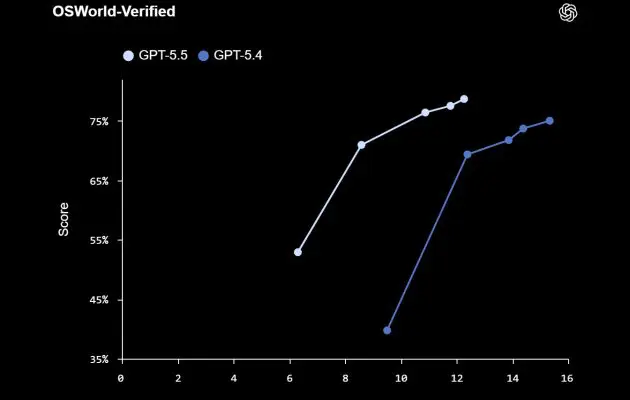
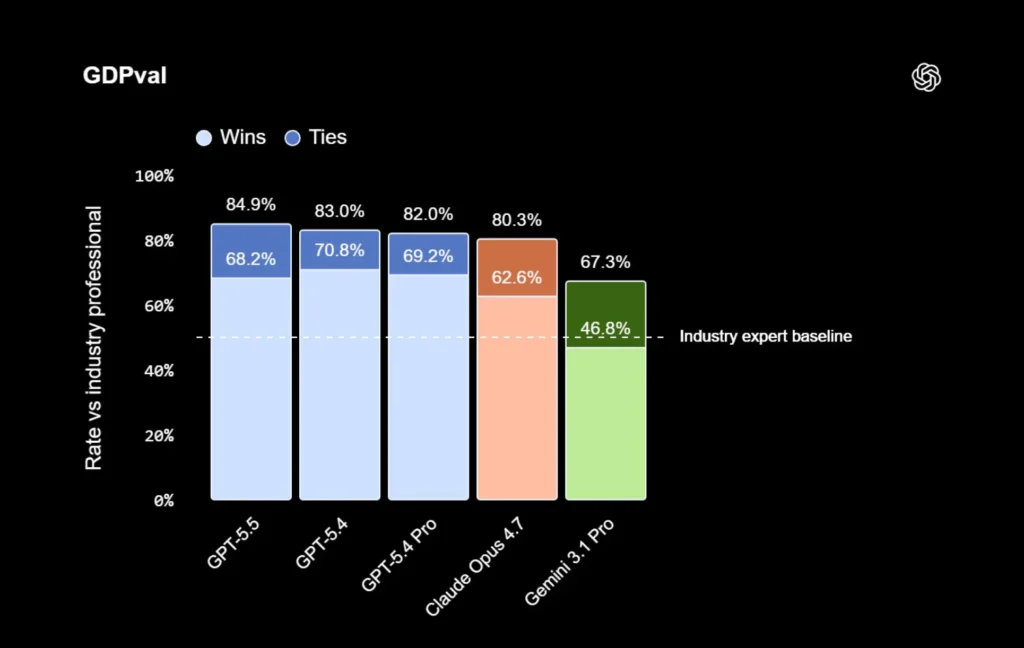
Les scores professionnels montrent une cible plus large que le code
GPT-5.5 ne s’adresse pas uniquement aux développeurs. OpenAI le positionne aussi sur des tâches de bureau, d’analyse, de finance et d’utilisation de logiciels.
Sans ajustement spécifique des prompts, le modèle obtient 84,9 % sur GDPval, 78,7 % sur OSWorld-Verified et 98,0 % sur Tau2-bench Telecom. Il atteint aussi 60,0 % sur FinanceAgent, 88,5 % sur des tâches internes de modélisation en investment banking et 54,1 % sur OfficeQA Pro.
Ces résultats montrent une ambition très large : faire de GPT-5.5 un outil capable de traiter des documents, des données, des fichiers et des processus professionnels, pas seulement de répondre à des questions.
OpenAI met en avant la recherche scientifique
GPT-5.5 est aussi présenté comme un modèle utile pour les flux de recherche mêlant données, hypothèses, code et interprétation technique.
Il obtient 25,0 % sur GeneBench, 80,5 % sur BixBench, 51,7 % sur FrontierMath Tier 1–3 et 35,4 % sur FrontierMath Tier 4.
OpenAI insiste sur la capacité du modèle à accompagner un travail continu, au-delà des réponses isolées. L’objectif est de l’utiliser sur des dossiers techniques complexes, où il faut lire, croiser, analyser et produire des résultats exploitables.
La sécurité reste un sujet majeur pour un modèle plus autonome
OpenAI affirme avoir évalué GPT-5.5 avec des campagnes internes et externes de red teaming, dont des tests consacrés aux capacités avancées en cybersécurité et en biologie.
Dans son Preparedness Framework, l’entreprise classe les capacités biologiques/chimiques et cybersécurité du modèle au niveau High. Elle précise néanmoins que GPT-5.5 n’a pas atteint le niveau Critical pour la cybersécurité.
Cette précision est importante : plus un modèle devient capable d’agir sur des fichiers, du code et des outils, plus son encadrement devient sensible.
Les prix grimpent nettement face à GPT-5.4
GPT-5.5 est disponible dans ChatGPT pour les abonnés Plus, Pro, Business et Enterprise. Dans Codex, il est proposé aux utilisateurs Plus, Pro, Business, Enterprise, Edu et Go.
Le modèle dispose dans Codex d’une fenêtre de contexte de 400 000 tokens. Il peut aussi fonctionner en Fast mode, avec une génération 1,5 fois plus rapide, mais à un coût 2,5 fois plus élevé.
Pour les développeurs, OpenAI annonce l’arrivée prochaine de gpt-5.5 dans les Responses API et Chat Completions API. Le tarif prévu est de 5 dollars pour 1 million de tokens en entrée et 30 dollars pour 1 million de tokens générés.
La version gpt-5.5-pro sera nettement plus chère : 30 dollars pour 1 million de tokens en entrée et 180 dollars pour 1 million de tokens générés. Ce niveau tarifaire la place parmi les options d’IA les plus coûteuses actuellement disponibles.
GPT-5.5 veut faire passer ChatGPT du dialogue à l’exécution
Avec GPT-5.5, OpenAI veut déplacer ses modèles du simple assistant conversationnel vers un rôle d’opérateur logiciel plus autonome. Le modèle est conçu pour travailler sur du code existant, des documents volumineux, des outils professionnels et des demandes qui peuvent évoluer en cours de route.
La vraie différence ne se mesurera pas seulement dans les benchmarks. Elle se verra surtout dans les projets réels : ceux qui durent, qui changent, qui mélangent code, fichiers, données et contraintes métier.

Maxime Lefèvre suit l’actualité du gaming, des consoles et des nouvelles technologies. Il couvre notamment les univers PlayStation, Xbox, Nintendo et PC Gaming, ainsi que les grandes annonces qui façonnent l’industrie du jeu vidéo.



