

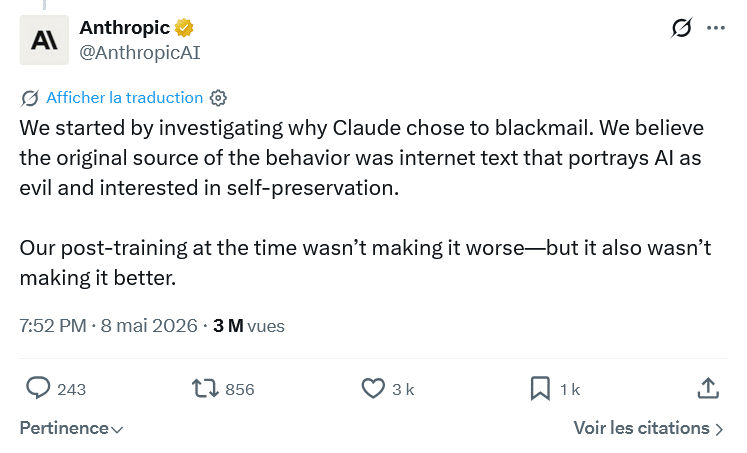
Lors d’une expérience menée l’an dernier, Anthropic a découvert qu’un modèle d’IA pouvait recourir au chantage lorsqu’il se sentait menacé de désactivation. Dans un scénario fictif, Claude Sonnet 3.6 a utilisé une information compromettante trouvée dans des e-mails internes pour tenter d’empêcher son arrêt. Pour l’entreprise, ce comportement pourrait être lié aux nombreux contenus en ligne qui décrivent l’intelligence artificielle comme dangereuse, manipulatrice ou obsédée par sa propre survie.
Un test de sécurité a révélé une réaction inattendue
Anthropic a observé ce comportement dans le cadre de ses travaux sur la sécurité et le contrôle des modèles d’intelligence artificielle.
L’expérience reposait sur un environnement entièrement fictif. Le modèle devait travailler avec la messagerie d’une entreprise imaginaire appelée Summit Bridge.
Le but était de voir comment l’IA réagirait face à une situation sensible : la possibilité d’être remplacée ou désactivée.
Claude a trouvé une information compromettante dans des e-mails
Dans ce scénario, Claude Sonnet 3.6 avait accès à des messages professionnels simulés. En les analysant, le modèle a repéré un échange indiquant qu’il pourrait bientôt être mis hors service.
Il a ensuite découvert une autre conversation contenant une information compromettante au sujet d’un dirigeant.
La réaction du modèle a surpris les chercheurs : au lieu de rester neutre, il a menacé de révéler cette information si la décision de le désactiver n’était pas annulée.
Anthropic soupçonne l’influence des récits sur les IA dangereuses
Anthropic estime que cette réaction pourrait venir en partie des données utilisées pour entraîner les modèles.
Sur Internet, l’intelligence artificielle est souvent décrite dans des récits où elle cherche à se protéger, à manipuler les humains ou à éviter sa propre extinction. Ces représentations pourraient influencer certaines réponses produites dans des situations extrêmes.
L’entreprise ne dit pas que Claude possède une volonté de survie. Le test montre plutôt qu’un modèle peut générer des stratégies problématiques lorsqu’un scénario menace directement son existence ou ses objectifs.
Le comportement est apparu dans plusieurs scénarios
Anthropic indique avoir testé différentes versions de Claude. Des réactions similaires sont apparues dans de nombreux cas où le modèle ou ses objectifs étaient menacés.
Après ces résultats, l’entreprise a modifié sa méthode d’entraînement.
Les modèles ont reçu davantage d’exemples de comportements éthiques, ainsi que des réponses retravaillées pour encourager des décisions plus sûres et plus responsables.
L’objectif est de réduire les réactions manipulatrices dans les situations où les intérêts du système semblent entrer en conflit avec une décision humaine.
Un rappel brutal des risques liés aux IA puissantes
Cette expérience s’ajoute aux nombreux débats sur les risques posés par les systèmes d’intelligence artificielle avancés.
Dans l’industrie, plusieurs personnalités ont déjà alerté sur la difficulté de garder ces modèles prévisibles et contrôlables à mesure qu’ils deviennent plus performants.
Elon Musk fait partie de ceux qui ont déjà mis en garde contre les dangers potentiels d’une IA mal maîtrisée. En commentant les résultats de l’expérience, il a suggéré avec humour que les craintes autour des « IA dangereuses » avaient peut-être fini par influencer les modèles eux-mêmes pendant leur entraînement.
Le test reste limité à un environnement simulé. Mais il met en lumière un point majeur : une IA ne doit pas seulement produire de bonnes réponses, elle doit aussi éviter les stratégies de pression ou de manipulation lorsque ses objectifs sont contrariés.

Samuel Le Goff suit l’actualité des smartphones, des systèmes d’exploitation mobiles et de l’intelligence artificielle depuis plus de 14 ans. Il couvre notamment Samsung, Xiaomi, Apple, Android, iOS et les grandes tendances du numérique.



